This article goes through how to use Real-time Voice Recognition within ODMS.
Note: You must have a Dragon Profile configured with ODMS for this to work please follow the guide here on configuring the Dragon NaturallySpeaking settings. Real-time Voice Recognition settings can be configured please follow the guide here.
The Real-time Voice Recognition feature is most similar to using a USB microphone with Dragon NaturallySpeaking’s DragonPad. It features a text-based window in which a user can dictate and see their audio being transcribed while they speak. The window features playback controls, text editing facilities and a tool bar to save and export the dictation.
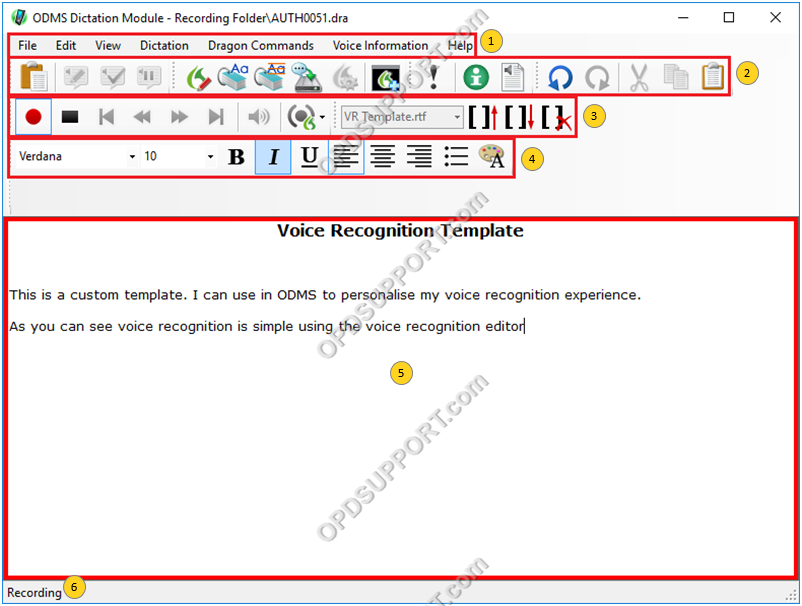
1. Window Toolbar
2. File Options
3. Playback Controls
4. Text Formatting tools
5. Dictated text / editor window
6. Recording Status
Making a New Recording
There are a number of ways to begin a new Real-time Voice Recognition recording:
- Click on the Do Real-time Voice Recognition in the main window.

- Click Voice Recognition > Do Real-time Voice Recognition
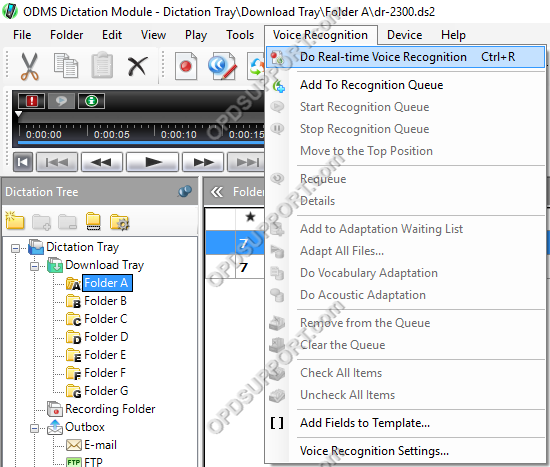
- Configure the New Button to start Voice Recognition editor when pressed.
- Click Tools > Options > Workflow.
- Select Direct Recording.
- Under [NEW] Button Operation enable the option Voice Recognition Editor.

Dictating into the Real-time Voice Recognition Window
Now that the window is open, simply press the Record button on the device and begin speaking. The
window will change color around the border to notify the user that it is in record mode.
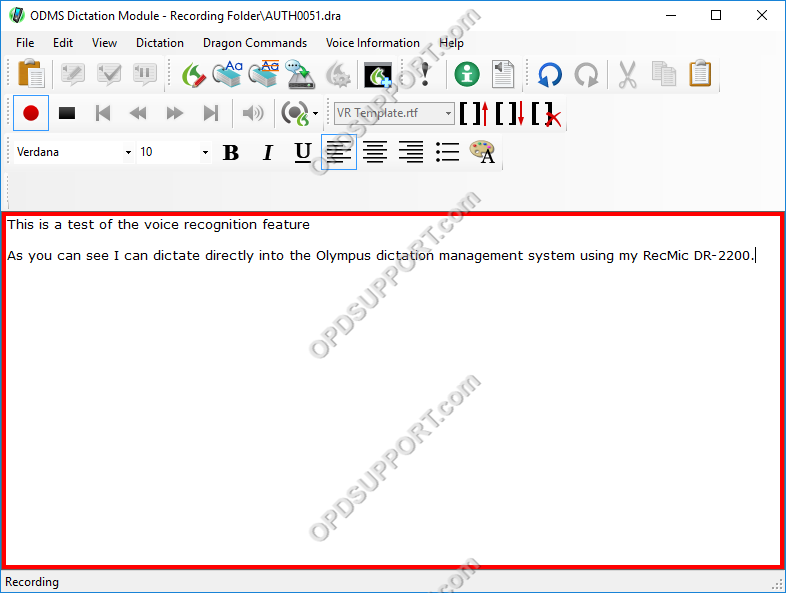
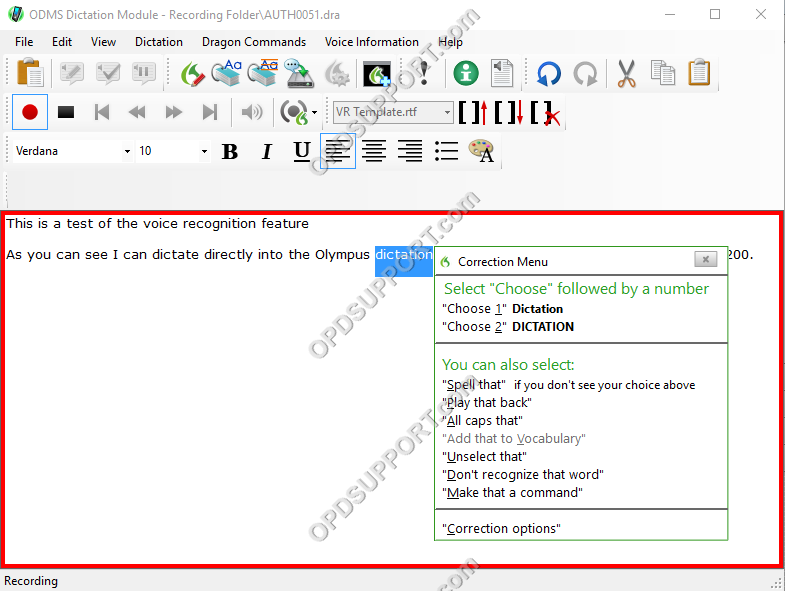
Performing Corrections
Correcting text is simple and uses the same procedure as performing correction within the
DragonPad.
- Simply say “Select [word]” and the Realtime VR window will highlight the selected
word. - To then correct the word, choose from the list of numbered items by saying “choose [number]” or say
“Spell that” if the desired word does not appear in the list.
Saving a File
Once the recording has been made click on File and then select the following options:
Finished – This will set the audio file in transcription finished status and exports the text to a document.
Send for correction – This will set the audio file in voice recognition finished status and saves the text document so it can be sent to a typist for correction.
Pending – This will put the audio file in pending status so the user can continue recording later.